
In 2021, Ania Molenda and Andrea Prins contacted us about a project called "Beyond The Essay: New Ways of Critical Reflection", where they are researching forms of online reading, writing and publishing with a specific focus on the essay in the field of architecture critique. Based on the results of their interviews with publishers and institutional partners, such as Valiz, Archis, ArchiNed, Torque Editions, dpr-barcelona, Institute of Network Cultures, and Framer Framed, we started a conversation on publishing tools and methods. Within our meetings we narrowed the scope down to the research question: how can digital publishing be a support system for critical reflection and engagement?
We decided to particulary focus on critical reflection and engagement with text, and to connect the Beyond the Essay research to an ongoing series of more-than-computational scripts that we have been working on in the past years that engage with reading and writing in collective and machinic ways. These scripts connect to a shared interest within Varia around collective publishing, slow computing, situated tool making, and the choice to work with open licenses and free software tools.
In Varia's practice of collective infrastructure making, we often consider the sociality that is inherent within the making and using of certain tools. We like to work with open ended systems and extensible structures that allow us to weave processes with each other and with others by adapting, extending, and transforming them.
For the Beyond the Essay workshop sessions we proposed to continue with three scripts developed within and around Varia, that engage with text in collective situations and respond to existing computational artefacts. The first session focused on a collective annotation system (using a spellbook of __MAGICWORDS__), the second one on indexing formats (inversing these formats into x-dexing processes), and the third one on the similarity measuring algorithm word2vec (turned into word2complex).
Each of the scripts ended up structuring possible circulation, writing and reading experiences of readers, writers and publishers alike. How can we think of ways for computing text otherwise, to reconsider how readers, writers and publishers can engage with each other through text?
Scripts
__MAGICWORDS__
__MAGICWORDS__ have started being used in this way by amy pickles and Cristina Cochior during a Read & Repair session on Digital Solidarity Networks (2020), and have been re-used in multiple other sessions since.
__MAGICWORDS__ is an open ended system for collective annotation of a text, using small instructions that can be activated during a collective reading experience. In the field of software, and specifically in the MediaWiki software, magic words appear as words with special programmatic functions, connecting a specific cue to a programmatic action, such as adding the current time on a page. Within the context of Varia's research, the __MAGICWORDS__ are used to manually perform programmatic gestures with the text without the involvement of code.
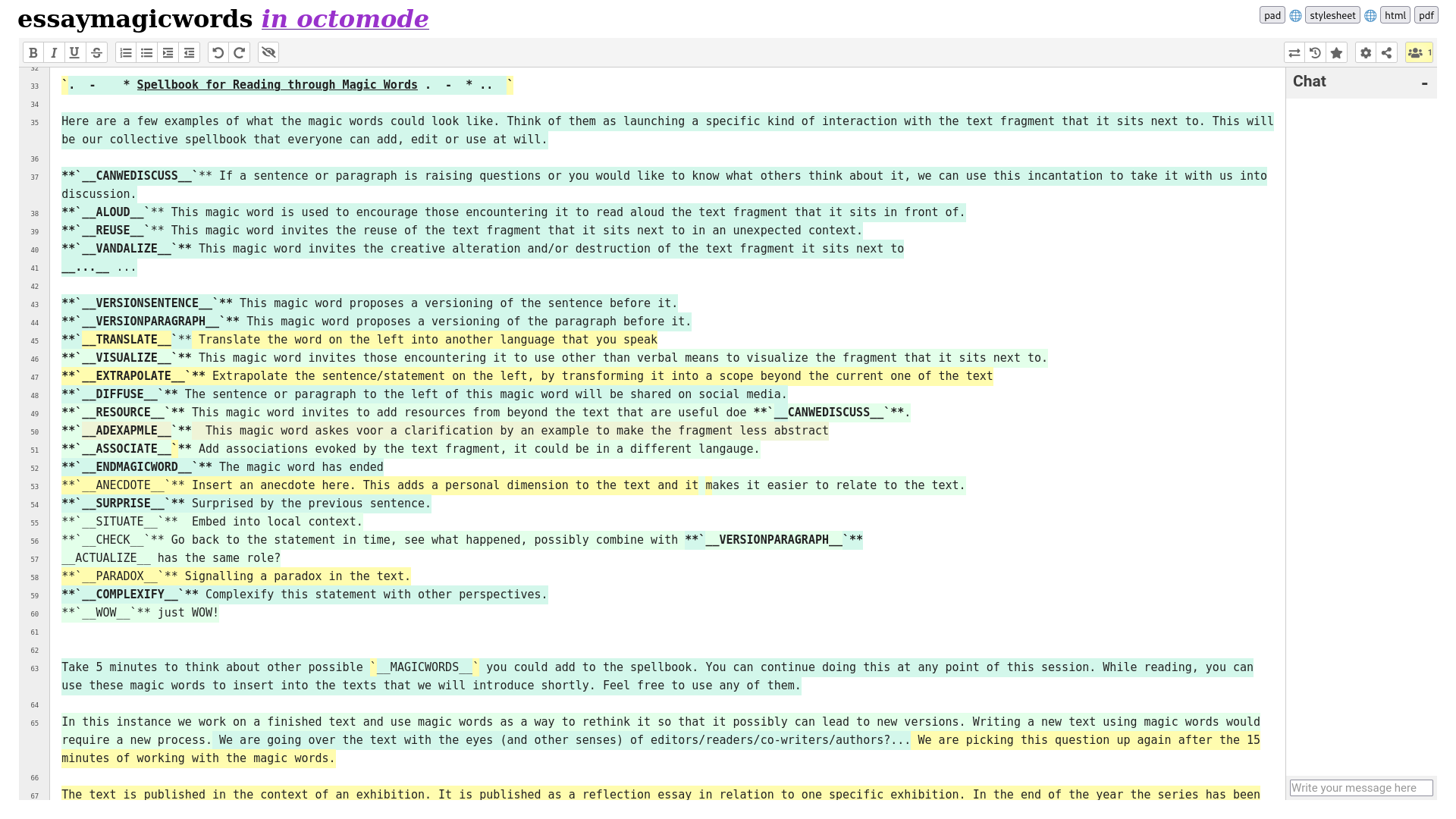
Magic words operate as prompts, inviting other readers to interact with the text in a specific way, ranging from __SAYITOUTLOUD__, __REPEATTHIS__ or __CANWEDISCUSS__. A set of magic words is collected in a spellbook, which stays open for new additions that may come up while reading.
Magic words emerged from a curiosity to see what kind of social incantations can be evoked through making custom prompts for each other, and how such prompts affect a moment of being together with text. As such, they become a tool to describe relations between text & reader, reader & reader, place & text, place & text & reader. While going over the __MAGICWORDS__ in the session we had together with Ania and Andrea, we were surprised how they also become an annotation system in which the intention of the comment is formulated by the name of the tag; this changed the relation of the comment with the text by inviting participants to imagine all sorts of different ways to speak back to that what is written.
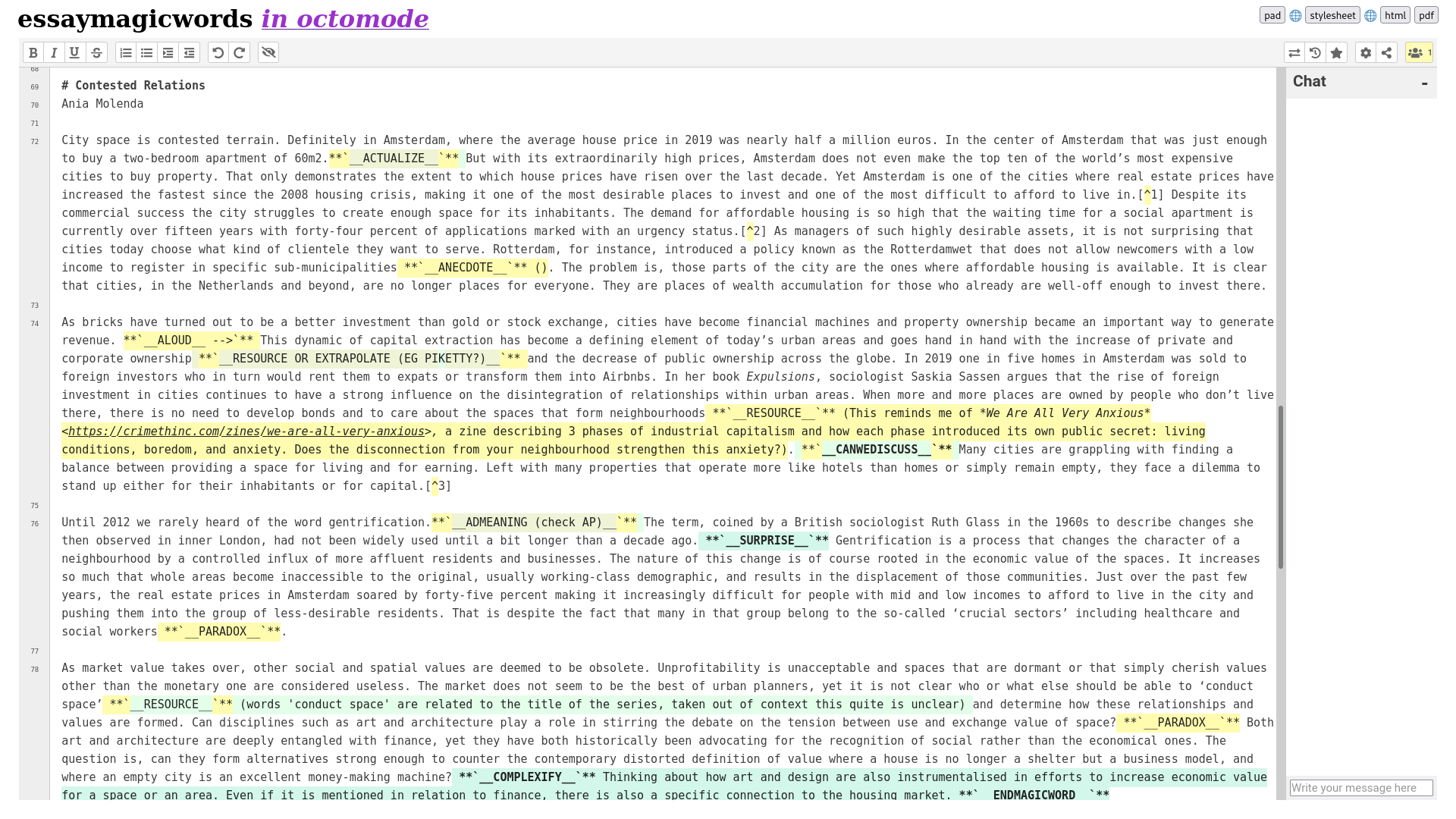
x-dexing
x-dexing was made by Jara Rocha and Manetta Berends to navigate and cross the book Iterations (2020), and appeared in a couple of other workshops and different versions since.
x-dexing is a cross-reading practice that through chance operations guides the reader in going over a body of texts. Contrary to an index, the x-dex invites to perform a non-linear distribution of attention across textures, semantics and aesthetics of the texts at hand.

While x-dexing, we read a collection of texts (materials) from a particular perspective (handles) across forms (text, color, curves, absences). To start with x-dexing, you are prompted to choose one piece of material, handle and form. In the next step, you are invited to write a score: a short set of rules for a particular way of reading. As a last step, you execute your own score, visualing the ruleset in a trace. X-dexing can happen in a concentrated manner, engaging with materials, given scores or invented ones, using these forms or others. But it can also be operated slowly, along time, in an ongoing way.

If “indexing” would be about gaining access through the illusion of completeness, the x-dex is about situated unfoldings, about letting go of fixitude and about handing over for a little longer; a form of generative relationality that is not providing with control nor indication, but a sort of playfulness and imaginative re-entanglement. Perspectives, feelings, aesthetics or uneasiness are not only brought to the table by the agents that share materials, but by the emergent x-dexer as well. Together they contribute to an explicit toolset for handling difference patterns, operate with worldly absences, and score open questions.
word2complex
word2complex is a continuation by Manetta Berends and Cristina Cochior (2021) on the collective unfolding of word2vec in Algolit (2017).
word2complex is taking the algorithm word2vec as starting point for a discussion around how users can read alongside algorithms and how algorithms construct machinic readings of text. As a reading exercise, word2complex investigates how algorithms order our experience and understanding of relationality between different words, by calculating semantic distances and context similarities. By staying close to the logics of word2vec, word2complex aims to rethink contextual ways of calculating and proposes to form semantic distances between contexts in more-than-computational ways.

Word2vec derives meaning not from semantics but from structure, relation and repetition, which it then turns to vectors in a multi-dimensional space. In word2complex, participants respond to such a way of processing text through a form of slow processing. In the first step, they count the amount of times a word appears in the text. In the second step, they rebuild the context of the word in the different sentences they encouter where the word is being used and in the third step, they relate the words with each other, resulting in text patterns.

Language analysis algorithms are pervasive in an online realm that is heavily text-based. Particularly word2vec is often used to cluster, make suggestions of related items, to translate to other languages, or to bring up results in search engines. By following the particular logic of the algorithm but leaving space for interpretation and co-production of meaning with those present, word2complex attempts to keep the complexity in operations of language processing through situated readings.

Reflection
Forms of collective annotation, close reading and cross-linking, as proposed by the three scripts above, invite the formation of a social environment in and around text. They create space to engage with the ideas within a single text, to find connections between multiple texts, or to relate the text to a specific context or situation.
In response to the question what it means to critically reflect on or engage with an essay, we propose to depart from the inherent sociality of text, by not (only) focusing on reading and writing critical content, but to consider and question how this content can be read or written. The three scripts therefore propose experimental methods for reading and writing. The scripts take a collective approach (inserting tags and annotations together to complexify the inherent collective life of an essay, as is the case in __MAGICWORDS__), a generative approach (creating a set of proposals for reading across perspectives through a set of essays, as is the case in x-dexing), or a critical stance to machinic forms of reading (performing computational operations —specifically for finding patterns in a set of essays— without using code, as is the case in word2complex).
Connecting computational approaches to text to the field of architecture and (digital) publishing, allowed us to consider the three experimental proposals for reading and writing practices in relation to multiple perspectives, those of the reader, the publisher and the author. How would these otherwise fixed positions of a reader, writer and publisher be affected by a shift caused through more collective approaches? What happens when the scripts are used to create intensified moments of engagement (as a format for a public event) and a range of publishable material (the outcome of the scripts)? Which __MAGICWORDS__ would a group of architects insert in the latest edition of Oase? What would a series of x-dexing sessions generate, when applied to a recenlty published book around housing and living? Which text patterns would emerge from reading across a series of essays around climate change?
The instruction based format of the scripts above invites versioning, variability and transformation, making them adaptable to different groups and moments. They have been (re)used in different contexts, such as workshops or events, and by different constellations of people, including Varia members and peers. They have been important scripts for us in shaping our collective practices, which not only include the design and publishing work we do, but also in the organisation of public events.
Next to an interest in collective work, the scripts also feed a curiosity for more-than-computational* practices. __MAGICWORDS__, x-dexing, and word2complex are all grounded in forms of computing, structuring, and processing and refer to specific computational artefacts: MediaWiki's magic words, the index as structuring device, and the word2vec algorithm. The scripts stretch these artefacts as a way to challenge their authority. Versioning them, making space to form interpretations, creating a possibility for comparison along the way; things can be done differently! These acts of re-situating computational artefacts have turned into a technological artistic research practice, positioned between the fields of art & design and software studies.
*This is a playful twist on the phrase "more-than-human"; we are still trying to find words to refer to the research based practices around algorithms, tool-making and language that we have been close to in the recent years.